Sync
Syncing is the process by which Nethermind updates itself to the latest block and current network state. There are several ways (sync modes) to sync a Nethermind node, each differing in speed, storage requirements, and trust assumptions.
Snap sync
Snap sync allows a node to perform the initial synchronization and download of network state up to 10 times faster
than using fast sync. This mode is enabled by default for most of networks that support it, and can be configured with the Sync.SnapSync configuration option.
Do not enable snap sync on a previously synced node. Only do so when syncing to the network for the first time.
The sync speed and download size has to do with the specific way in which network's state is stored in a node—Merkle trees.
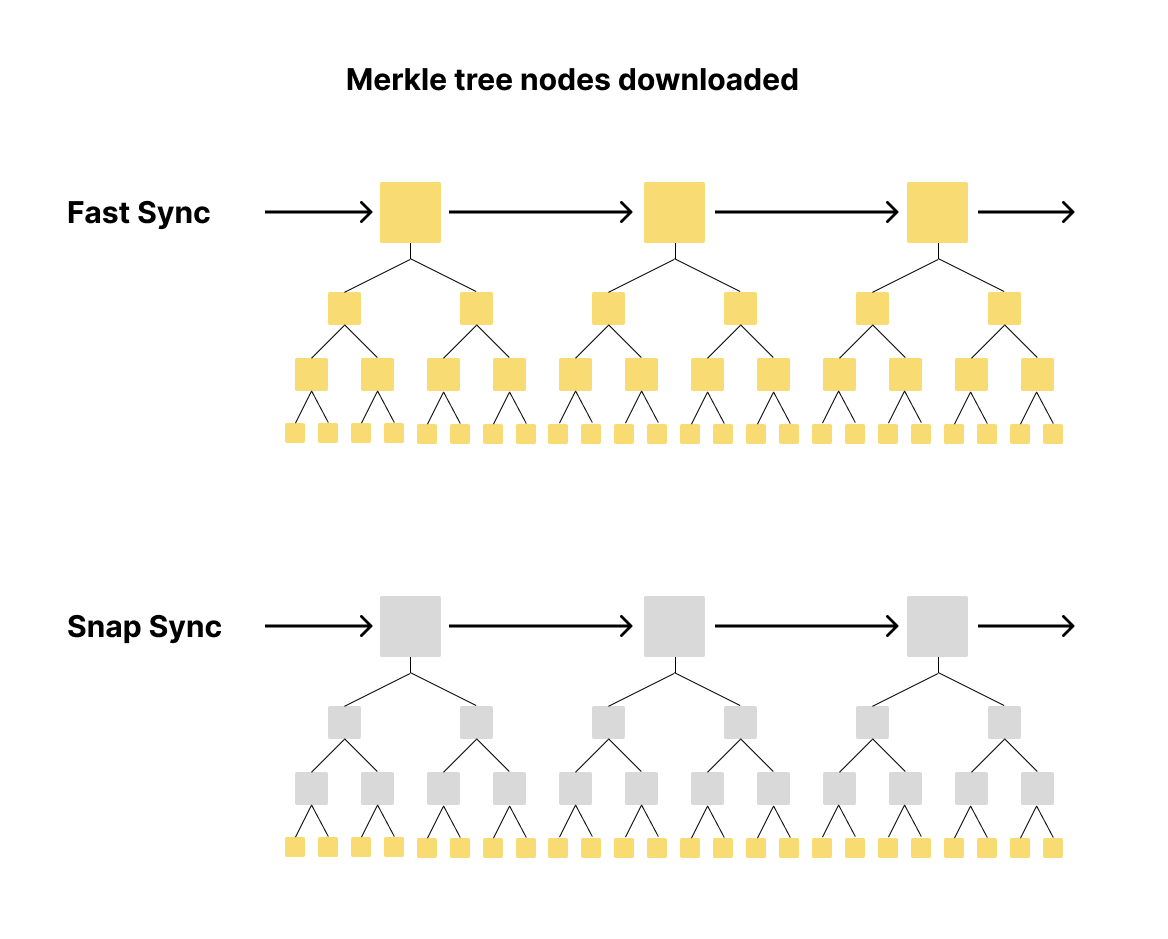
With fast sync, a node downloads the headers of each block and retrieves all the nodes beneath it until it reaches the leaves. By contrast, snap sync only downloads the leaf nodes, generating the remaining nodes locally which saves time and packets downloaded.
Fast sync
After completing the fast sync, Nethermind can answer questions like "What is my account balance now?" or "How many XYZ tokens does a particular exchange hold at the moment?". This mode can be configured with the following configuration options:
Sync.FastSyncSync.AncientBodiesBarrierSync.AncientReceiptsBarrierSync.DownloadBodiesInFastSyncSync.DownloadHeadersInFastSyncSync.FastSyncCatchUpHeightDeltaSync.PivotHashSync.PivotNumberSync.PivotTotalDifficulty
Fast sync has multiple stages. Nethermind uses a pivot block number to improve fast sync performance. The pivot block data is automatically updated after initialization of the client and consists of the block number, block hash, and block total difficulty if any. Before synchronizing state data, Nethermind synchronizes in two directions—backward from the pivot block to 0 for headers and forward to the head of the chain for headers, blocks, and receipts. Forward sync might be very slow (5 to 50 blocks per second), so having a fresh pivot block is crucial.
After downloading the block data, Nethermind will start state sync (downloading the latest state tree nodes). It provides an estimate for the download size and progress, but the real value may be different from the estimation. Because of this, sometimes sync may continue even when it shows ~100% finished. The other important component is sync speed—if the network or file system causes the state sync to go much slower than ~1.5 Mbps on average, Nethermind will start downloading some parts of the tree repeatedly. You may be surprised to see something like 58000MB / 53000MB (100%) in such cases. This means it has downloaded around 5GB of data no longer needed. If sync is very slow (extended beyond 2 days), your setup will likely not catch up with the chain progress. After the state sync finishes, you will see the Processed... messages like in archive sync, which means that Nethermind is in sync and is processing the latest blocks.
At the last stages of the sync, the node will repeatedly display the branch sync progress and change the block number to which it tries to catch up. This stage should take from 30 minutes up to 2 hours. If it lasts much longer, you may be unable to catch up with the network progress. One of the best indicators that you are close to being synced is combined ~100% state size progress and nearly 100% branch sync progress.
A single restart of Nethermind during the fast sync may extend the sync time by up to 2 hours because Nethermind has to rebuild the caches by reading millions of values from the database.
Archive sync
Archive sync is the heaviest and slowest sync mode but can answer questions like "What was my account balance 2 years ago?" or 'How many XYZ tokens were held in the custody of a particular exchange in 2022?". Archive sync can be enabled by choosing the respective archive configuration for the network you want to sync. By convention, such configurations suffixed _archive.
While archive sync can be completed very quickly (in minutes or hours) for some small networks, the Ethereum Mainnet sync would take several days, depending on the speed of your disk and network connection. The database size in archive sync is the biggest of all sync modes, as it stores all the historical data.
Explanation of some logs during archive sync:
- At the beginning, you may see the
Waiting for peers...messages while Nethermind tries to discover nodes it can sync with. Downloaded 1234/8000000shows the number of unprocessed blocks (with transactions) downloaded from the network. For the Ethereum Mainnet, this value may be slower than processing at first, but very quickly, you will see blocks being downloaded much faster than processed. Empty blocks can be as small as 512 bytes (just headers without transactions), and full blocks with heavy transactions can reach a few hundred KB. Nethermind shows the current download speed (calculated in the last second) and average (total) speed since start.Processed ...shows the blocks that the EVM has processed. The first number shows the current head block number; then you can seeMGas/s(megagas per second)—current and total, thentps(transactions per second)-current and total, andblk/s(blocks per second). Thenrecvqueue (transactions signature public key recovery queue),procqueue (processor queue). Both the recovery and processor queues are designed so that when too many blocks are waiting for processing, only their hashes are kept in memory, and the remaining data are stored in the database. Thus, the queues numbers that you can see will be capped by some number.Cache for epoch...shows Ethash cache needed for block seal verification (Ethereum Mainnet only). Caches will be calculated every 30k blocks (length of an epoch) and can also be calculated for the latest blocks broadcast on the network. After the archive sync finishes, you will see theProcessed...message appearing on average every 15 seconds when the new block is processed.
MGas/s, tps, and bps values should not be treated as comparable as they may differ massively on different parts of the chain. For example, when blocks are empty, you may see very high bps values with very low (or even zero) tps and MGas/s values as there are no transactions and no gas for EVM processing, and blocks are very light. On the other hand, when blocks are filled with heavy transactions, bps might be very low while MGas/s will be very high. It is even possible that you will see a lot of very light transactions where tps will be high while bps and MGas/s will be average.
Sync time
Sync time heavily depends on the hardware used for the node, network speed, and peering. We are constantly pursuing to make it as fast as possible. Below is a brief on how the sync time looks on different machines and various chains (tested with Nethermind v1.21.0).
- High-end VM
- Mid-end VM
- Old-spec VM
Hardware configuration:
- Cloud provider: Akamai (formerly Linode)
- CPU: AMD EPYC 7601, 16 vCPU
- Memory: 64 GB
- Storage: 1.2 TB, ~40k IOPS
- Mainnet
- Goerli
- Sepolia
- Gnosis
- Chiado
The high-level data on major sync milestones:
- Attestation time: 2h 3m
- Full sync time: 7h 3m
The detailed breakdown of sync stages:
- Snap sync phase 1: 1h 58m
- State sync: 4m
- Old headers: 1h 27m
- Old bodies: 1h 55m
- Old receipts: 3h 2m
The high-level data on major sync milestones:
- Attestation time: 2h 49m
- Full sync time: 4h 58m
The detailed breakdown of sync stages:
- Snap sync phase 1: 2h 49m
- State sync: 0.5m
- Old headers: 11m
- Old bodies: 1h 2m
- Old receipts: 1h 5m
The high-level data on major sync milestones:
- Attestation time: 8m
- Full sync time: 1h 9m
The detailed breakdown of sync stages:
- Snap sync phase 1: 8m
- State sync: 0.3m
- Old headers: 12m
- Old bodies: 21m
- Old receipts: 22m
The high-level data on major sync milestones:
- Attestation time: 13h 40m
- Full sync time: 17h 17m
The detailed breakdown of sync stages:
- State sync: 13h 40m
- Old headers: 1h 46m
- Old bodies: 1h 31m
- Old receipts: 2h 3m
The high-level data on major sync milestones:
- Attestation time: 20m
- Full sync time: 40m
The detailed breakdown of sync stages:
- State sync: 20m
- Old headers: 11m
- Old bodies: 8m
- Old receipts: 10m
Hardware configuration:
- Cloud provider: AWS
- c7g.2xlarge: 8 vCPU, 16 GiB memory
- Storage: 1 TB, ~10k IOPS
- Mainnet
- Goerli
- Sepolia
- Gnosis
- Chiado
The high-level data on major sync milestones:
- Attestation time: 5h 55m
- Full sync time: 12h 37m
The detailed breakdown of sync stages:
- Snap sync phase 1: 4h 35m
- State sync: 1h 20m
- Old headers: 1h 43m
- Old bodies: 2h 13m
- Old receipts: 4h 28m
The high-level data on major sync milestones:
- Attestation time: 1h 32m
- Full sync time: 4h 10m
The detailed breakdown of sync stages:
- Snap sync phase 1: 1h 19m
- State sync: 12m
- Old headers: 23m
- Old bodies: 49m
- Old receipts: 1h 35m
The high-level data on major sync milestones:
- Attestation time: 17m
- Full sync time: 1h 3m
The detailed breakdown of sync stages:
- Snap sync phase 1: 13m
- State sync: 4m
- Old headers: 15m
- Old bodies: 19m
- Old receipts: 29m
The high-level data on major sync milestones:
- Attestation time: 15h 54m
- Full sync time: 18h 28m
The detailed breakdown of sync stages:
- State sync: 15h 54m
- Old headers: 1h 4m
- Old bodies: 40m
- Old receipts: 1h 52m
The high-level data on major sync milestones:
- Attestation time: 13m
- Full sync time: 25m
The detailed breakdown of sync stages:
- State sync: 13m
- Old headers: 12m
- Old bodies: 5m
- Old receipts: 5m
Hardware configuration:
- Cloud provider: Scaleway
- CPU: Intel Xeon Processor E5-2620 v2, 2 vCPU
- Memory: 192 GB
- Storage: 1 TB, ~44k IOPS
- Mainnet
- Goerli
- Sepolia
- Gnosis
- Chiado
- Energy Web
- Volta
The high-level data on major sync milestones:
- Attestation time: 5h 55m
- Full sync time: 17h 1m
The detailed breakdown of sync stages:
- Snap sync phase 1: 4h 29m
- State sync: 25m
- Old headers: 1h 27m
- Old bodies: 3h 39m
- Old receipts: 8h 3m
The high-level data on major sync milestones:
- Attestation time: 1h 51m
- Full sync time: 5h 55m
The detailed breakdown of sync stages:
- Snap sync phase 1: 1h 40m
- State sync: 11m
- Old headers: 50m
- Old bodies: 1h 34m
- Old receipts: 2h 14m
The high-level data on major sync milestones:
- Attestation time: 16m
- Full sync time: 2h 9m
The detailed breakdown of sync stages:
- Snap sync phase 1: 15m
- State sync: 1m
- Old headers: 26m
- Old bodies: 45m
- Old receipts: 56m
The high-level data on major sync milestones:
- Attestation time: 15h 13m
- Full sync time: 17h 30m
The detailed breakdown of sync stages:
- State sync: 15h 13m
- Old headers: 3h 8m
- Old bodies: 50m
- Old receipts: 1h 25m
The high-level data on major sync milestones:
- Attestation time: 20m
- Full sync time: 40m
The detailed breakdown of sync stages:
- State sync: 4m
- Old headers: 1h 27m
- Old bodies: 1h 55m
- Old receipts: 3h 2m
The detailed breakdown of sync stages:
- State sync: 13h 7m
- Old headers: 2h 32m
- Old bodies: 51m
- Old receipts: 1h 11m
- Full sync time: 15h 20m
The detailed breakdown of sync stages:
- State sync: 14h 27m
- Old headers: 2h 42m
- Old bodies: 40m
- Old receipts: 58m
- Full sync time: 16h 10m
Resync from scratch
Note that resyncing a Nethermind node can take a considerable amount of time. It depends on your hardware, network connection, and the size of the chain.
- Stop Nethermind if it's running.
- In the Nethermind database directory,
nethermind_db, by default, look for a directory named after the network you want to resync and delete that directory. For instance, it'smainnetfor the Ethereum Mainnet. Normally, the database directory can be found at one of the following locations:nethermind_dbin the Nethermind's directory (by default)nethermind_dbin the Nethermind data directory specified by--data-dircommand line option (recommended approach)- The directory specified by
--db-dircommand line option
- Start Nethermind again and monitor its logs to ensure sync is progressing.